Abstract
This paper aims to investigate the relationship between asthma and smoking among African immigrants in California. The research problem is founded on the failure of many health studies to include African immigrants as a minority group in health studies that investigate the relationship between asthma and smoking. From this gap in the literature, this study seeks to answer one key research question, which pivots on finding out the association between asthma and smoking status among adult African immigrants in California. The dependent variable is asthma status and the independent variable is smoking status. The mediating variables are age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status. This study is quantitative because data will be collected from the California Health Interview Survey, which contains health statistics of different residents in the state.
Using the SPSS software, data would be analyzed using the descriptive statistical analysis method, which describes the main features of the data. Similarly, the inferential statistical analysis would be used for analysis, within the framework of the binary and multiple logistic regression methods to infer a relationship between the dependent and independent variables. Overall, the data analysis process would be hinged on the quantitative correlational research design and conceptualized within the principles of the socioecological theory. This study is important to state-based health agencies and medical professionals involved in asthma management because its findings could be used to develop health programs that target minority populations in California. It is also useful to academicians because it expands the body of knowledge surrounding the health of minority populations in the state. As a professional practice, this study would be integral to the advancement of asthma management among minority groups. It also has the potential of promoting positive social change by improving the health status of California residents through improvements in the health of immigrant populations.
Introduction
Health studies have often highlighted a relationship between asthma and smoking (Lee, Forey, & Coombs, 2012). Indeed, some researchers claim that most people who have asthma and smoke, at the same time are in double jeopardy because, as if tobacco smoke is not bad enough, their asthmatic condition could be triggered by irritants contained in the tobacco smoke, thereby leading to allergic inflammation of the bronchial tubes (Dutra, Williams, Gupta, Kawachi, & Okechukwu, 2014). This condition could lead to excessive mucus production, chronic cough, and phlegm (Lee et al., 2012). For many asthmatic patients, tobacco irritants not only manifest in the aforementioned symptoms, but also make breathing difficult (Gilreath, Chaix, King, Matthews, & Flisher, 2012). The relationship between asthma and smoking explains why many adults who develop asthma past their 50th birthdays often have a history of smoking tobacco (Dutra et al., 2014). My topic of study is centered on exploring the relationship between asthma and smoking among adult African Immigrants in California.
This study is important because African immigrants are a relatively understudied group. Furthermore, they are mostly underinsured than the general American population and experience significant variations, in terms of education and income outcomes, relative to other ethnic groups (Dutra et al., 2014). Because of their low socioeconomic status, they often experience inadequate medical care, which is often characterized by a lack of access to health care (Dutra et al., 2014; Gilreath et al., 2012). This problem often creates an inadequate recognition of asthma severity and the under-prescription of controlled medications by health care service providers. Besides poor socioeconomic conditions, African immigrants also suffer from other risk factors such as environmental exposures (because of the difficult working conditions they are often subject to) and respiratory tract infections that are often associated with low-income living (Dutra et al., 2014).
This study would have a positive impact on social change because it could help to reduce the impact of asthma incidences within the target population. Such an outcome would come, in part, from understanding the relationship between smoking and asthma. Understanding the relationship between the two variables could also help to improve the health outcomes and wellbeing of immigrant populations in California. The process could also shed more light on the factors that affect the relationship between the same. The insights drawn from this study could also be instrumental in understanding the social, economic, and political factors associated with Africans as an immigrant population in California. This analysis would provide a better understanding of their health outcomes and overall wellbeing. Additionally, the findings of the study would help to expand the body of research explaining the relationship between asthma and smoking among African immigrants in California. Thus, this study could promote positive social change by informing health policy decisions regarding smoking and asthma management in the state of California.
This first section of the study starts with a background review of the research topic and focusing on the research gap. That is followed by the problem statement, the purpose of the study, the research question, and the research hypothesis. I will then present the theoretical framework which this study is grounded on. The next topic will be the approach or nature of the study. The literature review starts with the literature search strategy followed by an extensive review of literature related to key variables and concepts. Key definitions, study assumptions, scope and delimitations, and limitations of the study will then be presented. The final part of this section will be to explain the significance of this study followed by a summary and conclusion.
Problem Statement
Researchers and medical experts have investigated the relationship between asthma and cigarette smoking. This relationship is founded on the fact that cigarette smoking causes the settlement of irritating factors on the air pathways, thereby worsening asthma attacks, or causing their resurgence (Tamimi, Serdarevic, & Hanania, 2012). Similarly, smoking often damages small hair-like structures (cilia) on the air pathways rendering them ineffective, thereby triggering asthma attacks (Tamimi et al., 2012). According to Currie and Baker (2012), about 25% of asthma victims are cigarette smokers.
African and Hispanic immigrants suffer a high risk of asthma fatalities compared to major ethnic groups in California (Findley & Matos, 2015). This is large because of socioeconomic disadvantages, poor housing conditions, and the lack of proper access to health care services (Findley & Matos, 2015). Smoking is also a contributor to this outcome because different studies have shown that many African immigrants often continue their smoking habits after arriving in the US (Amer & Awad, 2015). Researchers that have further investigated this issue point out that, West African immigrants experience fewer inhibitions to smoking because of a group-based cultural identity theory, which presupposes that they are free to smoke in America because of fewer social inhibitions that often prevented them from doing so in their home countries (Gatrell & Elliott, 2014). Nonetheless, this habit contributes to their poor health outcome.
Another set of contributors to the poor health outcome among African immigrants is the nature of jobs that they do in America. As shown by Braback, Vogt, and Hjern (2011), most immigrants often work in low-paying jobs that expose them to indoor and outdoor air pollution, which affects their overall health. Most of these jobs are concentrated in the agricultural, construction, and service sectors (Gatrell & Elliott, 2014). Some of the materials used in these industries contain harmful chemicals that further jeopardize their general health. For example, glues, insulation, and wood products contain harmful chemicals that are known to negatively influence the health of people exposed to them (Braback et al., 2011). Paints, cleaning products, and carpets also contain similar harmful chemicals, such as formaldehyde, which cause respiratory health complications.
Researchers have investigated the relationship between asthma and smoking among different races and genders. Corlin, Woodin, Thanikachalam, Lowe, and Brugge, (2014) assessed the relationship between asthma among Chinese immigrants living in Canada and their smoking behaviors. Other researchers have also investigated this relationship, relative to patients’ country of origin, residence, and education levels. Gatrell and Elliott (2014) explored the relationship between geographic differences and health status among immigrant groups in the US.
Most of the studies are based in developed countries that do not have many immigrant groups, and some of the studies are outdated. Few of these studies reflect the continuing changes in immigrant status or explain the relationship between smoking behaviors and asthma cases in regions that have multiple immigrant population groups, such as New York and California.
Although African immigrants are residing in the US, many health studies have often categorized them as African-Americans, thereby failing to distinguish between the health outcomes of African-Americans and African born US residents (Schenker, Casta-eda, & Rodriguez-Lainz, 2014). Furthermore, this population group is one of the understudied in the area of immigrant health because researchers have mostly focused on studying Hispanics and Asian immigrants (Gatrell & Elliott, 2014). The neglect of African immigrants, as a significant health cohort worth studying, betrays the spirit of public health, which promotes the provision of a holistic picture of health management (Moreland-Russell & Brownson, 2016). With this proposed study, I seek to fill this research gap by exploring the association between asthma and smoking among adult African immigrants in California.
Purpose of the Study
The purpose of this study is to determine the association between asthma and smoking status among adult African immigrants residing in California. I intend to use a quantitative correlational approach to explore the association between asthma and smoking status and selected demographic variables among adult African immigrants in California. The independent variables will be smoking status, age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status, and the dependent variable will be asthma.
This study is a secondary analysis of archived data relating to the incidence of smoking and asthma among immigrant groups (Africans) in California. The data are presented in the California Health Interview Survey (CHIS), which is an annual health database in the state. The data were developed from an annual telephone interview of more than 20,000 Californians and is considered the largest in America (Elk & Landrine, 2012). The CHIS database is appropriate for this study because it is not only free but also authoritative and easy to use. I also chose to use this database as the main source of data for this study because it is credible and reliable. Different professionals have used it to conduct health needs assessments, health research, and grant proposals (Elk & Landrine, 2012). Others have used it in news reporting and policy-making with great success. This record of accomplishment affirms its reliability.
Research Question and Hypotheses
The quantitative research question, hypotheses, and research variables for the proposed study are stated below:
- Research Question (Quantitative): What is the association between asthma and smoking status among adult African immigrants in California?
- Null Hypotheses (H0): There is no association between asthma and smoking status among adult African immigrants in California.
- Alternative Hypothesis (H1): There is an association between asthma and smoking status among adult African immigrants in California.
- Dependent Variable (DV): Asthma status
- Independent Variable (IV): Smoking status
- Mediating Factors: Age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status.
- Study Group: Adult African immigrants in California
Theoretical/Conceptual Framework
The socio-ecological theory will be the main conceptual framework for this study. Introduced in the 1970s by sociologists coming from the Chicago School, and revised by Bronfenbrenne throughout the 1970s and 1980s, this theory has been used to merge behavioral issues and anthropology issues in health studies (Moore, de Silva-Sanigorski, & Moore, 2013). The theory has five nested levels of interlocking behavioral and anthropological factors – interpersonal, organization, community, individual, and policy enabling environments. The interaction of these levels is summarized in the diagram that follows:
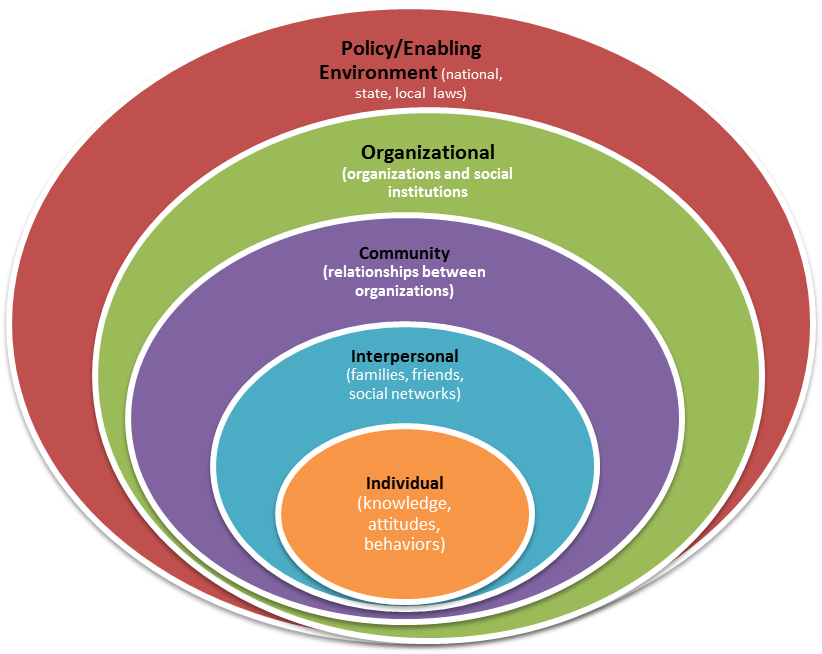
A key contribution of this theory to different fields of health and psychology is the understanding that the true comprehension of human growth should occur through a complete understanding of the ecological system, which supports or influences their behaviors (Yakob & Ncama, 2016).
The rationale for using this theoretical framework in this study stems from its ability to show different levels of personal and environmental factors affecting human behaviors and health outcomes. It does so by considering the complex interplay between the five layers of personal and environmental factors mentioned. This also justifies its application in this study because it has been used to successfully prevent domestic violence, child abuse, and promote community health (among other contributions in public health) (Gilioli, Caroli, Tikubet, Herren, & Baumgärtner, 2014). Its success in community health promotion is the main motivator for applying the theory in this study.
The socio-ecological model is ideal because it provides a holistic understanding of my research topic. Moreover, it takes into account the environmental factors that could affect the relationship between asthma and smoking (Sharma, 2016). The multifaceted nature of the model is appropriate for the study because I will explore the impact of several mediating factors, such as education, work, age, sex, and income (among other factors) in exploring the association between asthma and smoking among adult African immigrants in California (Coutts, 2016). In this regard, the model aligns with the variables of the study.
The socio-ecological model also incorporates our understanding of sociocultural factors that affect smoking behaviors among African immigrants because, as shown by previous studies, the smoking habits of this group of immigrants is partly caused by cultural factors (Bosdriesz et al., 2013). The socio-ecological model would help me to understand this bit of the analysis as well. Lastly, this model fits with the significance of the study, which is to inform public health policies and strategies regarding asthma management because the theory can provide a framework for preventing health problems.
This theoretical framework is relevant to my research issue because it would help me to uncover the personal and environmental factors that could explain an association between asthma and smoking among African immigrants (Onono et al., 2015). Marshall (2016) says smoking is a personal issue that is often associated with environmental factors, such as culture, peer influence, stress, and such factors. Similarly, asthma is a personal and environmental issue because it could be triggered or exacerbated by biological or environmental factors. Immigration also changes the environmental context that could affect human health outcomes (Arsen, 2013). In this regard, this framework could help to explain the environmental issues of African immigrants in California that could affect their health status. This way, this theory is useful to my research study because it provides a holistic perspective of our research issue. More specifically, it incorporates all my research variables because smoking is a sociological (behavioral) issue, while the health issue (asthma) affecting African immigrants living in California could be moderated by environmental factors.
Nature of the Study
I will use the quantitative correlational approach in the proposed study. This quantitative correlational approach aligns with the primary research question, investigating if there is an association between asthma and smoking among adult African immigrants in California. The asthma status is a quantitative measure because data on asthma reporting is usually presented in numbers. Similarly, smoking is often measured in terms of the number of people who do it. These two sets of data for the research variables are quantitative. Therefore, the selection of the quantitative technique is a natural process, based on the nature and characteristics of the variables that are measured (Creswell, 2014).
The quantitative approach applies to this research because my main source of research information – the California Health Interview Survey SPSS dataset and codebook is quantitative. There are different types of research approaches in quantitative studies. The main ones include descriptive research, correlation research, quasi-experimental research, and experimental research (Jacobsen, 2016). The correlation approach is the main approach to this study because it focuses on determining the existence and extent of a relationship between two or more variables. It aligns with my research topic because I also strive to investigate the association between asthma and smoking among adult African immigrants in California. Thus, the justification for using the correlation approach rests in the fact that it seeks to find out and interpret relationships between different variables (Guest, 2014).
The California Health Interview Survey is a statewide survey that contains quantitative data about different health issues in California. Supported by the California Department of Public Health and the Department of Health Care Services, this database contains health data obtained from telephone surveys that include the views of thousands of California residents (UCLA Center for Health Policy Research, 2017).
My research topic is centered on investigating the association between asthma and smoking among adult African immigrants in California. The research variables for this study include asthma, as the dependent variable, smoking as the independent variable, and age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status as mediating variables or covariates.
Literature Review
The prevalence and incidence of asthma worldwide vary across different regions and countries. According to the American Academy of Allergy, Asthma, and Immunology (2017), about 300 million people suffer from the condition globally. Similarly, there are 250,000 annual deaths attributed to the same condition, globally (American Academy of Allergy, Asthma, and Immunology, 2017). The number of people suffering from the condition is expected to increase dramatically by more than 100 million (American Academy of Allergy, Asthma, and Immunology, 2017). Thus, experts estimate that in 2025, the global population of people who will be suffering from asthma would be 400 million (Naturopath, 2013). Researchers claim that poor workplace conditions, such as exposure to toxic fumes, are responsible for the increase in asthma incidences (Naturopath, 2013).
According to the World Health Organization (2016), more than 1 billion people smoke tobacco worldwide. Statistics show that more men than women make up this number of smokers (World Health Organization, 2016). Similarly, they show that although the incidence of smoking is declining globally, the Mediterranean and African regions are still recording an increase in the incidence of smoking (World Health Organization, 2016). This finding means that smoking is primarily a problem that is concentrated among developing countries and within lower socioeconomic groups. Indeed, out of 5 million deaths that occur globally because of smoking, more than two-thirds of them are concentrated in developing countries (World Health Organization, 2016). These deaths are projected to increase because the number of smokers is expected to grow to between 1.5 billion – 1.9 billion in 2025 (World Health Organization, 2016).
The socio-ecological model will be the main conceptual framework for this study. However, other researchers have used other types of conceptual frameworks to explore the interaction between human factors and environmental factors while trying to assess or predict health outcomes. Kapp, Simoes, DeBiasi, and Kravet (2016) used the systems theory to investigate how immigration patterns affect health outcomes in America. Jayasinghe (2015) also used the same conceptual framework to explain how social issues affect health outcomes. Both researchers said that the systems theory provided a reliable conceptual framework for understanding how natural and social systems interact. They also said that the same framework properly conceptualized population health outcomes as dynamic, open, and adaptive systems. Broadly, these researchers have managed to demonstrate that human health outcomes are products of interrelated parts of subsystems, thereby enhancing our understanding of interactions between micro-meso-macro levels of health (Jayasinghe, 2015).
Relevant Factors Identified in the Literature Review
As evidenced by this literature review, there is increased attention to understanding the effect of asthma and smoking among immigrant communities, not only in America but around the world as well. This concern is partly caused by the rising prevalence of asthma and associated complications, globally. Most of the researchers in this literature review have explored the causal pathway of asthma and allergies. However, there have been contradictory and conflicting findings regarding the interplay between allergy and the socioeconomic determinants of health. Immigration status is at the top of the list of factors that have been poorly understood, but as seen from this literature review, many researchers have tried to explain it.
The focus on socioeconomic status was an important theme of this literature review because I am focusing on African immigrants whose health has been proved to be affected by their socioeconomic conditions. I have also explored the role of acculturation on the smoking habits of immigrants and found that the longer the immigrants stayed in the host countries, the higher their intensity and frequency of smoking. I have established that there are significant gender differences in acculturation among different immigrant communities that would ultimately affect their general smoking behaviors. While these studies (generally) have good merit in the way they were designed, I did not come across any study that focused on African immigrants as a unique sample population. The only studies that were close to our target population were those that sampled the health outcomes of African-Americans. However, these two populations are not the same. Additionally, the latter is not an immigrant group, per se. Based on this fact, there is a significant gap in the literature because health studies have failed to recognize the unique socio-cultural and economic dynamics of African immigrants that affect their health. This study seeks to fill this research gap by investigating the association between smoking and asthma among adult African immigrants in California.
Definitions
Asthma (Dependent variable) – A respiratory condition characterized by the presence of spasms in the nasal cavity. It often causes difficulty in breathing and inflammation of the lungs. Some common symptoms include wheezing, coughing, and shortness of breath (Arsen, 2013).
Smoking (Independent variable) – The inhalation of tobacco smoke through the burning of cigarettes; smoking is often a behavioral issue characterized as a recreational drug habit (Dutra et al., 2014).
Socio-ecological Model (SEM) – A model for understanding the interaction between personal and ecological effects of human behavior. The model is often used to identify behavioral and organizational leverage points that could be used to improve human health outcomes (Jayasinghe, 2015).
California Health Interview Survey (CHIS) – One of the largest health surveys in the USA that provides population-based, standardized health-related data for California. The data is often obtained from 58 counties in California and is collected using telephone surveys (UCLA Center for Health Policy Research, 2017).
Socioeconomic status – Socioeconomic status is the classification or the positioning of the social and economic standing of a person or group, relative to other populations. The social and economic metrics for classification could be influenced by people’s education standards, income, and work experience (Carroll, 2013).
Immigration status – This concept refers to the legal status of American immigrants. Immigrants may assume several legal statuses, including (but not limited to) permanent residency, refugees/asylees, and resident aliens, all of which allow people who are not born in the US to live in the country legally. The process of gaining an immigrant status is often a lengthy and complex one. This fact explains why people often need thorough consultations with an immigration attorney before seeking a legal status (Reingle et al., 2014).
Assumptions
According to Whaley (2014), assumptions are things that are believed to be true, but cannot be verified by the researcher. One key assumption in this study is that the findings from the California Health Interview Survey (CHIS) are credible and reliable. I believe that this information is free from errors because the dataset forms the bedrock of our research findings. I also assume that the findings obtained in this study are representative of all African immigrants in California, regardless of their social or cultural affiliations. The California Health Interview Survey, which is my main source of secondary data, investigated various health outcomes/issues (smoking and asthma were only two variables among many). It is assumed that the likelihood that the respondents thought the survey was only investigating the relationship between smoking and asthma is low. Hegde (2015) considers this feature as a strong predictor of internal validity and calls it the “double-blind technique,” where the respondents and the researcher both do not understand what the investigative process represents.
Some of the assumptions mentioned above affect the choice of using the CHIS database as the main source of data. More importantly, in the context of this research, I assume that the CHIS database is a credible and reliable source of information. Indeed, I have confidence that this database will provide the most credible and reliable information because it is the most comprehensive health survey in the state (UCLA Center for Health Policy Research, 2017). Additionally, the survey is based on a broad-based research strategy that includes the views of more than 20,000 respondents hailing from different counties in the state (UCLA Center for Health Policy Research, 2017). The credibility of using the database is also derived from the fact that the CHIS data have been successfully used to inform clinical health research, cancer research and formulate policies at institutional levels (UCLA Center for Health Policy Research, 2017). These facts are important in affirming the credibility of this study because the more the database has been used to inform other research studies, the higher its credibility and reliability in the context of this research review.
Scope and Delimitations
In this research, I seek to explore the relationship between asthma and smoking among adult African immigrants in California. Specific aspects of the research that are addressed in the research problem include smoking habits, asthma status, and African immigrants as the main target group. One factor that could have been important to the current study, but was excluded from it, was primary research to investigate the relationship between smoking and asthma among the target population. I did not include primary research because the study scope is statewide. Conducting statewide research could have required many resources and a lot of time that I did not have (Creswell, 2014). Consequently, relying on CHIS data was a better option. Another issue that could have been pertinent to this research is contextualizing the research problem to include African-Americans as part of the target population. However, I could not do so because, although African-Americans are not an immigrant group in California, they have unique social, political, and economic dynamics that are different from those of African immigrants, who were the target population.
Lastly, it would have been prudent to include secondary research data from other CHIS databases in this study because the data used in this report only apply to a survey conducted in 2015. Integrating previous CHIS databases would have helped to provide a long-term view of the research problem. However, I could not do so because the process could have taken a lot of time and resources, especially in integrating the two sets of data (Creswell, 2014). Furthermore, the data analysis process would have taken a long time to complete and possibly delayed the submission of this research study.
Limitations of the Study
According to Mangal and Mangal (2013), limitations of a study often refer to issues that are outside a researcher’s control. One key limitation of my study is that the findings obtained are limited to the time (or period) the data presented in the CHIS was collected. The use of secondary research data in this study comes with different limitations for me as the researcher, including limiting the information used to publicly available data. Similarly, the use of the CHIS data limits me to the current measurements used in the dataset, thereby constraining my ability to undertake a historical review of the same data because measurement standards often change periodically (Bowling, 2014). Lastly, since this study uses correlational studies, it comes with different limitations that include the difficulty of understanding which variable leads to a change in the other. In this regard, it would be difficult to understand causation from the use of this design. These factors outline the limitations of the study.
Significance of the Study
The findings of the proposed study would help to fill the research gap identified above by identifying unique attributes about Californian African immigrants that may affect the relationship between asthma and smoking. Findings could help to formulate health interventions that address these attributes to achieve the highest levels of success in reducing the rates of asthma cases. Moreover, the findings of this study could help health experts to develop focused interventions that appeal to unique African immigrant dynamics as a strategy to minimize the effects of smoking on the overall health of the African immigrants.
The findings of the proposed study could also contribute to the professional practice by informing policy decisions about smoking and outlining the mediating factors affecting the relationship between this variable with asthma. Mistakes made in the past highlight this fact because it took up to 50 or 60 years of research on tobacco use before governments started implementing policy decisions that reflected their findings (Pattanayak, Sunita, & Anshu, 2016). The proposed research could provide a reliable basis for the formulation of public health decisions affecting asthma management through an understanding of its relationship with smoking.
Lastly, the findings of the proposed study would help to promote positive social change by reducing the asthma attacks nationwide because African immigrants are among the worst affected, but one of the understudied groups. Exploring the relationship between the independent variable (smoking) and other mediating factors and the dependent variable (asthma), within this demographic, would be the first step in managing the disease and decreasing associated morbidity and mortality. Comprehensively, health care service providers might be able to have a holistic approach to asthma management that will consider all immigrant groups and not just the frequently studied ones – Asian and Hispanic immigrants.
Summary and Conclusion
In this section, I have shown that researchers have investigated the relationship between smoking and asthma. Particularly, they have demonstrated that these two variables share a positive relationship because increased smoking often increases asthma incidences. Their findings have also shown that smoking often irritates the air pathways, thereby leading to asthma. Similarly, they have also shown that the smoking habit damages hair-like structures (cilia) along the air pathways, leading to an exacerbation of the asthma condition. This data has often been presented as a general relationship between smoking and asthma. Specialized studies have often focused on age differences and income groups to explain the same relationship. Those that have further broken down the demographic divide have investigated the relationship between smoking and asthma among specific immigrant groups such as Hispanics and Asians. The relationship between smoking and asthma among African immigrants is a relatively under-researched area because studies have always neglected this immigrant group.
I seek to fill this research gap by exploring the relationship between smoking and asthma among adult African immigrants using a quantitative correlational study design. The main variables for this study are smoking as the independent variable and asthma as the dependent variable. My main source of data will be the CHIS dataset. I hope that this research will result in a better understanding of the association between smoking and asthma among adult African immigrants in California. The findings of this study could have a positive impact on social change because they could help to reduce the impact of asthma within the target population. Furthermore, they could inform policy decisions affecting the research issue.
Research Design and Data Collection
Introduction
The purpose of this study is to determine the association between asthma and smoking status among adult African immigrants in California. I intend to use a quantitative correlation approach to explore the association between asthma and smoking status and investigate the influence of selected demographic variables (age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status) on this same relationship. The independent variable will be smoking status, and the dependent variable will be asthma. The hypothesis states that there is an association between asthma and smoking status among African immigrants living in California. The findings of this proposed research could help to fill a research gap, which exists because previous researchers have not extensively explored the relationship between the aforementioned variables among African immigrants in California.
This section contains five parts or sub-sections. The first part is the research design and rationale, which explains the research variables and their connection to the research design. The second part contains details of the methodology used in the research. In this sub-section, the information about the target population, sampling procedures, power analysis, instrumentation, operationalization of constructs, data management, data analysis, procedures for recruitment, participation, and data collection are outlined. The third part of this section outlines the threats to validity, while the fourth part outlines the ethical procedures governing the research process. The last part of this section is a summary of the main tenets of the section.
Research Design and Rationale
As mentioned in the previous section, the purpose of this research is to determine the association between asthma and smoking status among adult African immigrants in California. The dependent variable is asthma status, while the independent variable is smoking status. The moderating variables are age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status.
The research design for this study is the quantitative correlation approach. This design is often used to explore the association between two or more variables in research (Armijo-Olivo, Stiles, Hagen, Biondo, & Cummings, 2012). There are two main variables (asthma and smoking) in this study, as seen from the research question, which states, “What is the association between asthma and smoking status among adult African immigrants in California?” There is an association between the design and this research question because the variables stated in the latter are quantitative (measurable). For example, asthma status is often measured in quantitative metrics, and smoking status is also measured quantitatively. Furthermore, the California Health Interview Survey (CHIS) dataset used in this study measures the two variables in numbers (quantitative). These factors limit the application of the qualitative technique, which measures subjective outcomes. Collectively, these factors explain the justification for using a quantitative approach. The use of the correlation design is also appropriate for this study because it measures two or more variables (Chan et al., 2013).
In this study, I seek to explore two variables, which are smoking and asthma status. Indeed, the research design has a connection to the research question. The use of the quantitative correlation approach comes with limited time and resource constraints because the relationship under investigation (the association between asthma and smoking status) usually involves a deep analysis of data and a careful evaluation of demographic data to understand the relationship (Hassan et al., 2015). However, the use of secondary research data to investigate the same relationship has alleviated this problem, and the time taken to explore the association between smoking and asthma is small. Furthermore, since secondary data is used in this research, there are limited resources needed to find out the association between the dependent and independent variables because the data is already published and does not require the researcher to use additional resources to get it.
The quantitative correlation design chosen for this study is consistent with other research designs capable of advancing knowledge in the health care practice because it opens up abundant opportunities for understanding the association between asthma and smoking status for future researchers interested in exploring the association further (Hoffmann, Bennett, & Del Mar 2013). However, it is important to point out that the research design is a form of descriptive approach and does not necessarily explain which of the variables studied influences the other. In this regard, it provides a good starting point for investigating the relationship between asthma and smoking by allowing researchers to understand the strength and direction of the association between the two variables without necessarily explaining the details surrounding the causation. Thus, future researchers can narrow the findings down to understand the intricate details surrounding the causation, experimentally, or otherwise.
Methodology of Research
Target Population
There are inadequate research studies that have investigated the association between asthma and smoking among adult African immigrants. Based on this gap, the target population for this research is adult African immigrants in California. This target population comprises of men and women above 18 years of age. Additionally, they must have originally emigrated from Africa and assume the status of first-generation immigrants living and possibly working within California, USA.
I will use 11 years CHIS secondary dataset (2005-2015) yielding a sample size of 1,130 respondents. I discern no issues with the internal validity as the California Health Information Survey design and data collection procedure is the same for all the years (2005-2015). I estimate that this sample size is large enough to make inferences about the association between asthma and smoking status among adult African immigrants in California because the CHIS 2005-2015 database includes 12,948 Blacks/African American respondents (UCLA, 2017). Thus, using a sample of 12,948 people, a target population of 1,130 is estimated to be around 9% of the total population sample in the CHIS database. This percentage is within the sample size requirements outlined in most social research studies needed to make inferences about statistically significant relationships (Faber & Fonseca, 2014). I used various sample size calculators (Creative Research Systems, Raosoft, Survey Monkey, GPower, and National Statistic Service) for my target population and yielded no more than 400 respondents. Thus, an actual sample size of 1,130 for my target population is three times the minimum required sample size.
Sampling and Sampling Procedures used to Collect Data
The main source of data and information for this study is the CHIS database. Since my main source of information is attributed to the source of secondary data, the sampling strategy mirrors the same plan present in the original secondary data. The CHIS 2005-2015 dataset was developed through a random sampling technique where respondents had an equal chance of being selected for the study (UCLA, 2017). This sampling strategy is often lauded for reducing selection bias and improving the reliability of the associated findings. Additionally, the CHIS dataset was developed by randomly selecting one adult respondent in each household that chose to participate in the study. The sampling strategy employed in the study was designed to meet two main goals. The first one was to provide local estimates of population-based health data for comparison across different counties in California, while the second one was to provide statewide population-based health data for all the ethnic and racial groups in California (UCLA, 2017).
The sampling strategy adopted in the CHIS dataset was drawn from the dual-frame random-digit-dial (RDD) method, which included a sample of the respondents’ views using telephone surveys (UCLA, 2017). Besides the landline sample, the CHIS dataset also included a statewide cell phone sample of the overall population. The landline and cell phone samples described two separate groups of respondents that characterized the data. The researchers administered these samples through a computer-assisted telephone interview that included both the statewide landline random digital dial and the statewide cell phone sample. The landline sample was stratified according to county demarcations, groups of small counties, and sub-county areas (UCLA, 2017). Based on the nature of the data collection method, only those households that had a landline telephone were included in this sample.
The sampling frame used to develop the CHIS dataset involved the use of traditional random digit dial and cell phone random digit dial sampling frames. The inclusion criterion was households, which had a landline or cell phone. The inclusion criterion also included the views of respondents who were adults (18 years and above) (UCLA, 2017). Comparatively, the exclusion criterion included respondents who were under 18 years and households that lacked either a cell phone or a landline. These frames were used to get the views of different respondents in the state of California by understanding the source materials and devices from which the sampling population was drawn from.
Power Analysis
Power analysis is an important aspect of this methodology because it outlines the procedures used to select the right sample size that could be reliably used to find out if there is an association between asthma and smoking status among adult African immigrants in California. To determine the minimum sample size, I used various reliable calculators developed by Creative Research Systems, GPower, Raosoft, Survey Monkey, and National Statistic Service. Using these tools, I obtained a minimum sample size requirement of 385 respondents based on a 95% confidence level, a 5% confidence interval, and a population of 2,000,000. This confidence level represents the level of surety that the inferences I will make after assessing the available data are reliable. The confidence level also insinuates the same position because it outlines the degree to which I am confident that my findings are true and reliable.
I used a confidence level of 95% because I wanted to have a reliable sample and it denotes a high level of precision for the sample used. I assume that the effect size of 1,130 people is adequate for drawing reliable conclusions about the relationship between the dependent and independent variables for the target population – African immigrants. The confidence level of 95% was used because many researchers who have done similar studies use it as a standard measure of confidence for their findings (UCLA, 2017).
Procedures for Recruitment, Participation, and Data Collection
This study is a secondary analysis of archived data (CHIS secondary dataset). CHIS researchers originally collected this data, which is the largest database in California. The main variables analyzed from the database include asthma status and smoking status. The analysis will include an attempt to statistically interpret the relationship between both variables and mediating variables. The benefits of using this data for this type of analysis are clear, but the barriers are also many, as argued by Faber and Fonseca (2014) who say the success of this type of data collection depends on the efficiency of health agencies and researchers to conduct reliable public health studies.
Data Management
Explaining the procedures for data management is important in this research study because it affects the credibility of research information (Jain et al., 2015). Data management also involves explaining the procedures for accessing data and the necessary permissions required to obtain such information. In the context of this study, the data analysis process explains the reputability of the information retrieved from the CHIS, contains an explanation of why the information retrieved from this secondary data source is important and represents the best source of data for the research. I gained access to the database through an open access online platform available at CHIS. Therefore, there was no need for getting special permission to access the information.
Although it is common practice that researchers get special permission to use secondary research data, this requirement is mostly applied to research information that is not freely available online (Jirojwong, Johnson, & Welch, 2014). However, this requirement was not applicable in my review because the information used is publicly available. However, I will seek permission before analyzing these CHIS secondary data.
Although using freely accessible data is acceptable in this study, it is important to use reputable data sources when undertaking this type of research. In the context of this study, the reputation of the findings, which I will produce, will only be as good as the reputation of the secondary data used. As mentioned in this study, the main data source was the CHIS dataset. This dataset was appropriate because it is statewide and is undertaken by a reputable organization. Furthermore, UCLA (2017), which undertook the study, has been collecting similar data since 2001 with relative success. Based on its good reputation, different professionals, including journalists, policymakers, and health experts, use its information. Thus, this source of data is appropriate for this study.
Instrumentation and Operationalization of Constructs
Instrumentation of Constructs
As mentioned in this study, the main source of data is CHIS. It is among the largest health interview survey in America and is conducted on an annual basis to provide information about different health topics (UCLA, 2017). Although the CHIS publish health data relating to different years, the data used in this study is CHIS 2005-2015.
Looking at the appropriateness of the CHIS data to the current study, I find that it is relevant and specific to the topic under investigation because the dataset provides health data relating to different ethnic and racial groups in California. A focus on African immigrants as one cohort in the study is ideal for my analysis because the current study focuses on this ethnic group as the target population. The dataset is also appropriate to the current study because asthma is a health topic investigated in the research data. Other health issues surveyed in the dataset include diabetes and obesity (UCLA, 2017). The inclusion of asthma as a relevant health issue in the dataset and the provision of health data relating to immigrants bring my attention to the appropriateness of the data to the current study.
The findings contained in the CHIS document are freely available to the public. Therefore, there is no special permission from the researcher needed to use the instruments. Based on the availability of the health data outlined by CHIS, different people, including policymakers, state agencies, and community organizations, find the resource useful in improving the health outcomes of their subjects.
A review of the reliability and validity of the values outlined in the research study reveals that both metrics are desirable because the CHIS data acts as a model for collecting state and local health data. This attribute demonstrates its reliability. Its use in advanced sampling and application methodologies also adds to the same metric because such evidence has been used to influence key policy changes in different areas of research (Mertz et al., 2014). Its credibility is also supported by the fact that the database contains information that would appeal to key stakeholders in the health sector. These published reliability and validity values show that the sources of data are relevant to the current research.
The CHIS database was used to collect health data across different ethnic and racial groups in California. In the past, it has been used to collect health data from all 58 counties in the state of California (UCLA, 2017). However, there are cases where the researchers have oversampled specific areas within the state that are heavily populated (such as Los Angeles and San Diego). The reliability and validity of the findings developed from the past use of CHIS have been confirmed through the involvement of large and diverse samples (UCLA, 2017). In other words, past users of the data established that the samples used in the dataset were representative of the ethnic and racial diversity of the state, particularly because the findings could be used to answer specific and important health questions of different ethnic and racial groups in the state.
The CHIS data has sufficient instrumentation to answer the research question. For example, I have established that the dataset contains health data about different ethnic and racial groups in California. This one instrumentation is useful in answering my research question, which focuses on one ethnic group – African immigrants. Other aspects of the instrumentation used to develop the CHIS are its consistency, flexibility, and adaptability. These attributes mean that the findings included in the report can be used to investigate new health issues and emerging trends among specific racial or ethnic groups. Lastly, the inclusion of spatial and geographic data in the CHIS dataset is another aspect of its instrumentation that would help to answer the research question because I can narrow down to a specific locality (California), which is at the core of my analysis. This type of instrumentation is often unavailable in national health data (Liamputtong, 2013).
Operationalization of Constructs
The research variables identified in the CHIS database were numerous though I utilized only a few variables that are related to my research question. In this study, two main variables were relied on to complete the research. They include the independent variable (smoking) and the dependent variable (asthma). In the CHIS database, race emerged as one variable that helped to define the target population – African immigrants. It was denoted by the term Self-reported African American (SRAA). Smoking is also another variable that was included in the CHIS database and it was denoted by the code SMKCUR. This variable indicated the number of people who were currently smoking. The same was true for asthma as a dependent variable because it was denoted by code ASTCUR. This variable helped to ascertain the current asthma status of the respondents. The main variables (asthma and smoking) are operationalized depending on how well they are categorized into measurable parts. The process of measuring the variables will be done empirically and quantitatively.
Dependent variable
The dependent variable for this research is asthma. Simply, asthma is a health condition, which manifests as a long-term inflammatory disease of the respiratory tract and difficulty in breathing (Tamimi, Serdarevic, & Hanania, 2012). The original researchers operationalized this variable according to the guidelines of the International Classification of Disease, which defines asthma as a chronic disease that causes pulmonary obstructions (WHO, 2016). However, broadly, the International Classification of Disease segments this disease in two categories. In the first one, three types of asthma are explained – extrinsic asthma, intrinsic asthma, and unspecified types of asthma, and in the second category, asthma is defined in four segments that include unspecified asthma, mixed asthma, non-allergic asthma, and predominantly allergic asthma (WHO, 2016).
Similar to how the original researchers operationalized this variable, I will also use the International Classification of Disease to operationalize the dependent variable because this standard is globally accepted and approved by the CDC (2017). The International Classification of Diseases is also approved by the World Health Organization and is globally accepted by practitioners in the health field, including physicians, nurses, and health information providers (WHO, 2016). The symptoms of asthma would have to be clinically proven to reach the threshold for diagnosing a patient as suffering from the condition. I will describe the frequency and percentage of African immigrants with asthma conditions who smoke, and those who do not smoke.
Independent variable
The independent variable will be smoking status. The original researchers used the International Classification of Disease to operationalize smoking as one of the variables in the dataset. This classification is enshrined in the diagnostic code ICD-9 of the International Classification of Disease database, which states that smoking is the inhalation of tobacco smoke (WHO, 2016). This code has also been used to cover several aspects of smoking behaviors, including nicotine dependence, newborns affected by smoking during pregnancy, and occupational exposure to tobacco smoke. The measure does not include people who smoke other substances, such as marijuana, or those who partake in other types of smoking.
I will also use the same operationalization metric to operationalize smoking as the independent variable. The reason for upholding the same metric is to maintain consistency in the operationalization of variables between the original and the current research. Furthermore, similar to how the merits of using the International Classification of Disease emerged in the analysis of the dependent variable (asthma), the same merits justify the use of the same criteria for operationalizing the independent and mediating variables in this study. The variable would be measured by counting the number of African immigrants who smoke or who have smoked in the past. In this regard, the computation would assume the form of frequency and percentage.
Mediating factors/variables
The mediating variables in this study include age, sex, years since immigration, marital status, alcohol abuse, education level, income level, and employment status. The CHIS database, which is the source of data for this study, defined these mediating factors as independent variables and not mediating variables as described above. Therefore, the above-mentioned variables were used independently to explain different health outcomes without any relation to the core variables under analysis in this study – asthma, and smoking. The same variables also had no relation with the target population – African immigrants. Additionally, the CHIS database used the above-mentioned mediating variables to explain different metrics associated with the sample population. Most of these metrics helped to provide valuable data such as the health status, insurance status, and lifestyle behaviors affecting the health outcomes of California residents. The variables were also used by the researchers to provide important descriptors surrounding the health of the sample population, such as their gender, ethnicity, age, and such as demographic factors. Thus, as opposed to having the mediating factors explaining specific health outcomes, the researchers used the mediating variables for descriptive purposes.
The strategy for operationalizing the mediating factors/variables, as described in the CHIS database, will not be the same one applied in this study. Instead, the moderating variables applied in the current research would be to understand the factors affecting the relationship between the independent and dependent variables. These variables would be important in making sense of the findings, with a specific focus on how they affect the outcomes observed. Furthermore, the moderating variables would be instrumental in understanding the social, economic, and political dynamics of the target population (African immigrants) that would further help to understand the findings.
The mediating effect due to the mediating factors would be developed from the mediation model as espoused by MacKinnon (2012) who says the model helps to explain causation. In the context of this study, the correlation would be applied to the independent and dependent variables, which are asthma and smoking. This analysis means that the mediating variables would be assumed to have led to the relationship between the dependent and independent variables and not the other way around where the dependent and independent variables affect the mediating variables. A mediation variable would be considered that way if it satisfies one of the following three conditions: if a change in the independent variable is responsible for a significant change in the dependent variable, if it significantly dominates the relationship between the dependent and independent variables, and if the lack of it correlates with the disappearance of the relationship between the independent and the dependent variables.
Data Analysis Plan
The data analysis plan is an important part of this research process because it would help me get useful information/findings from the research inputs. To undertake this process, I will use the SPSS statistical software tool.
Data Cleaning and Preparation
Before analyzing data with the SPSS software tool, I will participate in data cleaning and screening procedures to make sure that the inputs of the data analysis process are reliable and credible. However, I do not expect to have many errors or mistakes associated with the data inputs (used in the data analysis process) because the dataset used is from the CHIS, which is often a reliable and valid source of information. Nonetheless, to make sure that the information keyed in the SPSS software is credible, I will look out for the range data. This process will also involve checking for the minimum and maximum values associated with the variables of interest by analyzing scores associated with the descriptive data (Murari, 2013).
To make sure that the data is clean, I will also look out for “abnormal” responses. This process will help me understand whether the responses included in the analysis are legitimate, or not. My criterion for doing so would be counterchecking suspect responses with those of the majority respondents. The data screening process will also involve looking out for identical responses from the data to avoid cases of duplication (Perry, Barak, Neumann, & Levy, 2014). To make sure that this process is effective, I will investigate if there are cases of identical values, or near-identical values, to establish whether they have been posted erroneously, or they represent the same scores. If such cases are confirmed, I will choose to maintain one case/value and remove the duplicate value. The last step in the data screening process will involve manually checking for errors and mistakes associated with the data.
Unlike other data screening processes, there would be no specific analysis aimed at detecting specific issues because the focus would be to investigate whether there are any cases of oddities (Shaughnessy, Zechmeister, & Zechmeister, 2014). One criterion I will be used in preparing the CHIS data is looking out for “empty cases” where the values involved would be missing or insignificant. When such cases are established, such data would be omitted from the data analysis process.
Statistical Analyses Plan
Descriptive Statistical Analysis
The dependent variable, independent variable, and mediating variables would be described using descriptive statistical methods that include frequency tables with ranges and percentages. I will specifically use mean values as a measure of central tendency for mediating variables like age, income, and years since immigration. The frequency statistics would simply help to point out the number of times each variable occurs. Also, cross-tabulations will yield the frequencies and percentages for the variables. For example, it is instrumental in explaining the frequency of asthma among people who smoke. This statistical tool would be useful in describing the personal information of the sample. For example, researchers have used it to provide details about gender, educational qualifications, income, and such as demographic data. This type of information is applicable in understanding some of the moderating variables such as age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status.
Inferential Statistical Analysis (Logistic Regression)
For this study, I will utilize Logistic Regression as the main inferential statistical analysis. As part of the data analysis plan, the use of Logistic Regression will be central to the whole process because it would help to test the hypothesis, which states, “There is an association between asthma and smoking status among adult African immigrants in California.” The Logistic Regression method is applicable in this study because the dependent variable (asthma) is categorical/nominal and there are two levels of the dependent variable (Polit & Hungler, 2013). In other words, the probability of asthma occur because of smoking could only take two forms “yes” and “no.” This type of analysis will also help us to mimic the real-life scenario of mediating factors that affect the relationship between the dependent variable (asthma) and the independent variable (smoking). This analysis will be crucial in investigating the effect of mediating factors (sex, years since immigration, marital status, alcohol use, education level, income level, and employment status) on the dependent and independent variables. Its significance would be hinged on investigating whether there is a significant difference between two or more research variables. I will utilize both Binary Logistic Regression and Multiple logistic Regression.
Binary Logistic Regression
Similar to other regression methods, the binary logistics method is predictive (Denham, 2016). In this paper, it will be useful in predicting the relationship between the dependent and independent variables. To do so, there will be two values of “0” or “1” that would be used to explain an association between the two. A value of “1” would be used to denote the presence of asthma and the value of “0” would be used to denote an asthma-free status (Laerd Statistics, 2017). The binary logistic regression would also be pivotal in highlighting the strength of the relationship between the independent and dependent variables, as opposed to merely stating an association between both (Denham, 2016). This way I would be able to use the CHIS data to estimate the probability that asthma would occur among the target population because of smoking using a classification plot for purposes of category prediction.
In most studies, the probability of an outcome occurring should typically be more than 0.5 (this number is even higher than the probability of the event occurring by chance) (Laerd Statistics, 2017). An output of more than 0.5 would mean that smoking is associated with asthma conditions. This figure would help to predict the category of variables. Carrying out a predictive analysis would also be useful in understanding important attributes about the variables, including the percentage accuracy in classification, sensitivity (percentage of cases that manifest specific and observable characteristics), specificity (percentage of cases that do not manifest observable characteristics), the positive predictive value, and the negative predictive value. The effect of the mediating variables would be useful in articulating these indices of analysis (Laerd Statistics, 2017).
Multiple Logistic Regression
According to Warner (2012), the multiple logistic regression method is used for testing the association of one categorical binomial dependent variable and two or more independent variables. According to Denham (2016), this regression method is mostly used in understanding the effect of different independent variables on a dependent variable. In the context of this study, the multiple logistic regression method would be used in estimating the effect size of the mediating variables in the relationship between the independent and dependent variables. The capability of the method to investigate multiple relationships would be exploited in this regard by understanding the effect size of the mediating factors.
The multiple logistics regression method will also be instrumental in detecting any anomalies that may arise from an investigation of the relationship between the dependent and independent variables (Warner, 2012). This area of investigation would be instrumental in providing context for the investigation of the dependent and independent variables. Through this analysis, I will be able to understand the relative influence of one or more of the mediating variables on the relationship between asthma and smoking status (Warner, 2012). Thus, generally, the multiple logistic regression method would be complementing the binary logistic regression method because it would be providing context and a deeper meaning to the research process. Comprehensively, the use of both methods would help to provide a holistic understanding of the relationship between the independent and dependent variables.
Data Analysis Matrix Table
The data matrix table in Appendix 1 provides a visual summary of the descriptive analysis in the study. In the matrix table, there are four main concepts, which are aimed at describing the smoking behaviors among the immigrant population, understanding the occurrence of asthma within this population group, ascertaining the number of African immigrants in the study, and understanding how their demographic profiles affect the relationship between the dependent and independent variables. There is a common data source that would be used to collect this data – CHIS 2005-2015 Adult Data. Each of the concepts described in the data analysis matrix has its unique level of measurement, which is either ordinal or nominal.
I allocated ordinal measurements to concepts that could be described in the form of a range of quantitative variables. Lastly, the description of the demographic profile of the target population was measured nominally because they mostly included variables that were in one or two states. For example, gender could only be measured in terms of male or female. Educational qualification could be measured using a continuum of different states, such as high school diplomas, undergraduate education, postgraduate education, and the likes. The use of different levels of measurement in the analysis justified the use of the ordinal and nominal measurement techniques for describing the demographic profiles of the respondents. The data analysis techniques used in the descriptive analysis were frequency tables, percentages, or measures of central tendency.
Mock Tables
The mock tables in Appendix 2 paint a picture of how the statistical reports would be presented. The tables largely represent the findings of the descriptive and inferential analyzes and are tabulated using percentages and relevant statistical analysis tools. It is important to point out that each table is representative of a research study objective and has a detailed analysis of the procedures used to come up with the data.
Although I will use multiple statistical tests for this review, I will account for the possible errors that may occur from doing so by putting a stricter significance threshold for each test. For example, to affirm a positive association between asthma and smoking status, I will only consider values that are 0.5 to 1.0. This range is stricter than the normal range of proving such a relationship, which often varies from 0.0 to 1 (Wright-St Clair, Reid, Shaw, & Ramsbotham, 2014).
Part of the data analysis process will also involve the inclusion of mediating factors, such as sex, income, and education (among others), in the analysis. The justification for including these variables is their significant influence on smoking behavior and asthma development among the target population. Furthermore, it is difficult to have a perfect experiment because the compliance rate will not always be absolute and neither is the dropout rate. Consequently, introducing covariates in the analysis will help to clarify the relationship between the dependent and independent variables (Arkkelin, 2014).
The data analysis process will involve inferential analyses using correlation tests. Testing for correlations will involve analyzing values that range from -1 to 1. If I get values that are closer to 1, I will deduce that there is a strong relationship between smoking and asthma status among African immigrants in California (Rezaei et al., 2017). The opposite is also true because if I deduce a value that is closer to -1, I will assume that the two variables share a weak relationship. A value that is closer to 0, or 0 would mean that there is minimal or no linear relationship between the two variables as well (Mohini & Prajakt, 2012).
Threats to Validity
Threats to validity are issues that could affect the credibility of the research findings. Indeed, as Nieswiadomy (2012) observers, threats to validity may significantly undermine the reliability of any given research design. The main threat to validity for the current study is centered on the use of the CHIS database, which was the main source of information for this study. The failure to be part of the original research is one threat that suffices in this context because it means I was not privy to pertinent research information that could be instrumental to the current research. One threat to the external validity of the research is that it could not apply to migrant populations outside the context of the research region – California. Furthermore, it could be inapplicable to other racial or immigrant groups living in California because the current research only focuses on African immigrants in the state. The specificity of variables is also another threat to the internal validity of the study because different criteria for analyzing the variables may cause distortions in the findings. For example, a person’s smoking status may quickly change within the time a study is undertaken. This change may significantly affect the outcomes of the study.
To overcome threats to internal validity, I will obtain as much information about my sample population (African immigrants in California) as possible to get a better understanding of the respondents and to evaluate how their social, political, and environmental dynamics affect the study. This measure is useful in solving the internal threat associated with instrumentation (Lee, Crawford, & Wallerstedt, 2012). Standardization is also another technique I will use to overcome the same threat. In this approach, I will strive to consider the conditions under which the original study was carried out when developing the research findings because I am depending on the CHIS methods and data for my analysis.
I could also experience some of the same validity problems when analyzing external validity issues associated with the study because there is a problem associated with applying the findings of this study beyond the selected sample. One problem I could experience from this issue is the possibility that the secondary data used to develop the research findings may not apply to a different time, outside of the publication date (Fernandez-Hermida, Calafat, Becoña, Tsertsvadze, & Foxcroft, 2012). The secondary data used in this study was published in 2015, and this means that the findings may not apply to any other period under review. I may also experience the same problem with instrumentation because I have already established that the secondary data used was developed from telephone and cell phone surveys. The use of different instrumentation techniques in future research may yield different results. For example, if researchers used one-on-one interviews to collect data, as opposed to the telephone and cell phone surveys, the relationship between asthma and smoking status may change because the context of the investigation would change, possibly in favor of respondents feeling more obligated to take the research more seriously, as opposed to a phone interview (Arkkelin, 2014).
To overcome the external validity issues mentioned above, I will point out, in the findings section, that the results apply to a specific period. This way, the users would know the limitations of the study and consider the same when making future or past inferences about the relationship between asthma and smoking status among African immigrants living in California (Lang & Altman, 2014). This solution would be instrumental in solving external validity issues associated with the publication date for the CHIS data. To solve the problem of instrumentation, it is essential to include co-variation in the study when analyzing the data to understand the effects of the use of different instrumentation techniques when developing the findings (Lang & Altman, 2014). Similarly, standardizing the research process could help to avoid this issue because it would make sure researchers replicate the same context when conducting future studies (Lang & Altman, 2014).
Lastly, I do not anticipate any threats to construct or statistical conclusion validity in this study because I have already explained how each of the variables will be operationalized. Similarly, in this research, I have shown that the findings would only be limited to the African immigrants residing in California and those who are either smoking or have been diagnosed to have asthma.
Ethical Procedures
Any study that involves human participants is often subject to several ethical issues (Ndebele et al., 2014; Nicholls et al., 2015). The CHIS dataset used in this research, as the main data for review, is subject to these ethical issues. In this section of the study, I will explain how these ethical issues affect the treatment of data and the recruitment of participants and materials when formulating the research findings.
The ethical procedures used by the CHIS researchers to collect data were approved by UCLA. The ethical procedures that will be followed in the current study will also be based on the guidelines outlined by the Institutional Review Board (IRB) because I will apply to this institution to analyze data before conducting the statistical analysis. The current study will also involve an analysis of de-identified data to avoid cases of privacy infringement or confidentiality breaches. Data was stored safely in a computer and protected by a password, which only the researcher could gain access to. This safeguard ensured that no other person had access to the information besides the researcher (Nursing and Midwifery Board of Australia, 2012). Lastly, a credit will also be given to the original authors of the research to avoid cases where the readers could assume that the findings of the current study are the authors. This way, cases of plagiarism are avoided.
Summary
This section shows the research methodology utilized to answer the main research question. Binary and multiple logistic regressions will be used to test the association between asthma and smoking status among adult African immigrants in California. The dependent variable is asthma status and the main independent variable is smoking status. The moderating factors (other independent variables) are age, sex, years since immigration, marital status, alcohol use, education level, income level, and employment status. Secondary analysis of the archived data will be conducted after receiving IRB approval. I will conduct both descriptive and inferential statistical analyses for this study. I will complete a descriptive analysis using frequency tables, percentages, and measures of central tendency. I will also conduct the inferential analysis using bivariate analysis (Binary Logistic Regression) and multivariate analysis (Multiple Logistic Regression).
Quantitative correlation research is the main design used to answer the research question. It is based on the understanding that the research topic is a correlation study because the current research explores the association between asthma and smoking status among African immigrants in California. The main source of information is secondary research data, which comes from an independent survey by the CHIS. The SPSS software tool is also the main data analysis technique used in this study because of its ability to analyze large amounts of data. The correlation technique is the main SPSS tool applied in this study because of its ability to identify associations between two or more variables. The results of the data analysis process are presented in the next section, which outlines the results and findings of the study.
References
Denham, B. (2016). Categorical statistics for communication research. London, UK: John Wiley & Sons.
Warner, R. (2012). Applied statistics: From bivariate through multivariate techniques: From bivariate through multivariate techniques. London, UK: SAGE.